
Machine learning technology is reshaping how we interact with computers, make decisions, and process large amounts of information. It enables computers to learn and decide from data without explicit programming.
Understanding machine learning basics is crucial for professionals to do efficient work.
How does Machine Learning Work?
Machine learning is a part of AI that focuses on creating systems that learn from data. It includes creating models that analyze historical data, spot patterns, and predict outcomes.
These models use algorithms trained with labeled or unlabeled data. The core of machine learning is its autonomous improvement over time.
Basic Understanding of Machine Learning Models
Machine learning models are the frameworks that allow algorithms to process input data and generate predictions or decisions. Data scientists and researchers build models with suitable algorithms for specific problems.
Models are trained using labeled or unlabeled data for learning outcomes. Labeled data has known answers, while unlabeled data requires finding structure. Model quality depends on input data and chosen algorithm suitability.
A machine learning model can improve rendering processes in 3D rendering. It learns from past tasks to predict efficient settings for future jobs, saving designers and artists time and resources.
Machine Learning Algorithms Explained
Algorithms are the heart of machine learning. They are rules and stats machines use to learn from data. Various machine learning algorithms exist for specific tasks and data types.
By analyzing past data on task completion times and server performance, machine learning systems can allocate resources for optimal efficiency without being explicitly programmed.
Another critical aspect of machine learning algorithms is their ability to improve over time. As more data becomes available, these algorithms can be retrained or fine-tuned to enhance their accuracy and performance for better future outcomes. This iterative process makes machine learning so powerful, enabling computer systems to adapt continuously to new data and changing environments.
Professionals in machine learning must grasp the role of algorithms in selecting the right one. This is crucial for tasks like natural language processing or computer vision. The correct algorithms help build efficient models and offer insights for innovation.
As we explore machine learning more, it’s crucial to acknowledge its significant influence on different areas. From simplifying intricate 3D rendering to enabling advanced predictive analytics, machine learning algorithms are essential for professionals using high-performance computing and data-driven decisions.
Why Machine Learning is Important
There are machine learning applications in many sectors, boosting innovation and efficiency. It excels at analyzing vast data sets, revealing insights beyond human capability.
In 3D rendering, it predicts rendering parameters to speed up processes. For architects and professionals in interior design rendering, machine learning models can enhance design processes by suggesting optimizations based on pattern recognition and historical data.
The technology plays an important role in natural language processing. It helps systems comprehend human language accurately. This tech enhances human abilities and boosts productivity. Predictive maintenance relies on machine learning algorithms to anticipate equipment failures without human intervention.
Machine learning is valuable in data science for extracting insights from data gathered by various data mining methods. Data scientists use machine learning for strategic decision-making and innovation. Machine learning techniques push boundaries in computer science by developing advanced systems that can learn, adapt, and create artificial neural networks.
Machine learning’s significance is clear in its capacity to execute tasks without explicit programming. This adaptive feature enables systems to enhance with new data, which is crucial for applications like content recommendations or fraud detection.
As machine learning evolves, its role in boosting human intelligence is evident. It’s about enhancing, not replacing, human tasks to aid decision-making. For example, in quality control, machine learning detects defects missed by humans, ensuring consistency.
Different Types of Machine Learning
Machine learning has many learning algorithms for different problems and data. Professionals must know these types to pick the right tools for tasks like 3D rendering or choosing platforms for computation.
There are a few machine learning categories:
- Supervised learning algorithms;
- Unsupervised learning;
- Semi-supervised learning;
- Reinforcement learning;
Below, we will review each one in more detail.
Supervised Learning
Supervised machine learning is a machine learning algorithm that uses labeled data to learn a function mapping input to output. This learning resembles a teacher-student dynamic, where the algorithm learns from data to make predictions.
It’s common in applications with understood historical data, like regression for housing prices or classification for spam emails.
Unsupervised learning
Unsupervised machine learning, on the other hand, deals with unlabeled data. The goal is to explore the data and find some structure within it. Unsupervised learning algorithms are used for analyzing cluster data points and association tasks, such as grouping customers with similar buying behaviors or finding associations between different products.
These algorithms are particularly useful for exploratory data analysis, anomaly detection, and understanding complex data structures where the outcomes are unknown beforehand.
Semi-supervised Learning
Semi-supervised learning falls between two extremes, using labeled and unlabelled data. This method is useful when obtaining labeled data, which is costly or time-consuming.
Still, there is a vast amount of unlabeled data. It merges the advantages of supervised and unsupervised learning to enhance learning accuracy.
Reinforcement Learning
Reinforcement learning is another type of machine learning where an agent learns to make decisions by performing actions in an environment to achieve cumulative reward.
It’s used in various applications, from playing video games to self-driving cars, where the system must make a series of decisions that lead to a goal.
Different machine learning types have unique algorithms and uses. For instance, support vector machines are common in supervised learning for classification. Deep learning is a subset of machine learning that uses artificial neural networks with multiple layers for tasks like image and speech recognition.
Machine Learning vs. Deep Learning
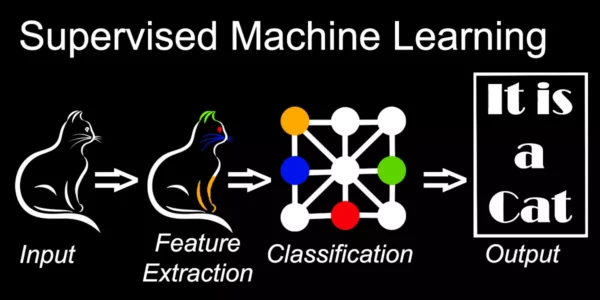
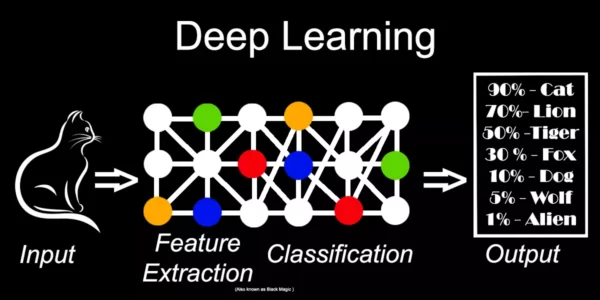
Knowing the difference between machine learning and deep learning is vital for professionals. Both can enhance processes in areas like cloud rendering. Deep learning is a type of machine learning that uses neural networks with layers. These networks mimic the human brain’s neural network.
Deep learning algorithms learn from large unstructured data sets. They excel in computer vision and natural language tasks. Machine learning algorithms, on the other hand, can be linear or nonlinear. Deep learning processes data hierarchically. Neural networks handle input and output data and learn features directly, which benefits tasks like image recognition.
Deep learning has revolutionized the field of artificial intelligence by providing a way to approach previously unsolvable problems. Its ability to learn from large amounts of data and its high accuracy make it an invaluable tool for machine-learning platforms requiring sophisticated pattern recognition capabilities.
AI vs. Machine Learning
Artificial intelligence (AI) and machine learning are often interchangeable but differ. AI is a broader concept that refers to machines or computer systems that can perform tasks that typically require human intelligence.
This includes reasoning, learning, perception, and problem-solving. On the other hand, machine learning is a subset of AI that focuses specifically on developing systems that can learn from data.
Machine learning helps achieve AI, a top method for smart systems. Developers use algorithms to create programs that learn and improve. Learning from data sets it apart from rule-based AI approaches.
The distinction between AI and machine learning is significant for professionals in deep learning and those who work with neural networks. AI encompasses a wide range of technologies, including robotics and expert systems. Machine learning focuses on creating computer algorithms to learn from data and make predictions.
Pros and Cons of Machine Learning
Machine learning offers a range of benefits, but it also comes with its own set of challenges. One of the main advantages of machine learning is its ability to automate decision-making processes and uncover insights from data. For example, in machine learning for 3D rendering, machine learning can automate adjusting rendering parameters to optimize speed and quality.
Yet, machine learning has downsides. A major challenge is acquiring labeled training data, which is significant, especially for small entities lacking data access. Moreover, machine learning models can be opaque, hindering decision-making understanding.
Another concern with machine learning is the potential for bias. If the training data is biased, the machine learning model will likely inherit that bias, leading to unfair or unethical outcomes. This is a critical consideration for machine learning researchers and practitioners, as they must ensure that their models are as unbiased and fair as possible.
Despite challenges, machine learning benefits often surpass drawbacks, especially for complex tasks. It can reveal insights humans can’t at an unmatched scale and speed.
Benefits of Machine Learning in Various Sectors
Machine learning applies to various sectors, such as healthcare, finance, and entertainment. In healthcare, predictive analytics forecast patient outcomes and personalize treatment plans. Also, in finance, algorithms detect fraud and manage risks, and in entertainment, they recommend content.
For data science pros, machine learning is crucial for data analysis. It helps find patterns and predict future trends.
Challenges and Limitations of Machine Learning
The technology offers advantages but faces data quality challenges. Models rely on training data quality, and acquisitions and mining methods are crucial in machine learning.
Another challenge is the complexity of the models. As machine learning algorithms advance, they get more complicated to comprehend and explain. This poses challenges for deploying models in practical scenarios. Stakeholders may need explanations for model decisions.
Last but not least, it demands substantial computational power, which might challenge certain users. Cloud render nodes and specialized GPU servers for machine learning can help, offering the essential computational resources for training and executing machine learning models.
Machine Learning Use Cases
Machine learning’s flexibility enables its use in many situations, transforming task execution in different sectors. For example, in 3D rendering, machine learning predicts maintenance needs for render farms, preventing downtime. In architecture, machine learning detects anomalies in design, spotting structural problems early.
Another significant use is in data science, where machine learning helps analyze data. It’s handy for researchers who want to enhance algorithms and boost model performance.
It also plays a key role in creating platforms for cloud services. These platforms use tools to offer users powerful computational resources like GPU servers. These resources, like training deep learning models, are crucial for tasks needing heavy processing power.
Machine learning boosts computer systems, enabling tasks once exclusive to humans. It includes complex pattern recognition crucial for computer vision’s growth.
The Future of Machine Learning
The future of machine learning is bright, with continuous advancements expected in machine learning methods and techniques. As machine learning platforms evolve, they will offer more sophisticated cloud services and solutions, making it easier for professionals to access the computational resources they need, such as cloud render nodes and dedicated graphics hardware.
One of the most exciting prospects is further developing deep learning algorithms, which are expected to become even more efficient and capable. This will profoundly impact natural language processing and computer vision, where neural networks are already making significant strides.
Additionally, the future of machine learning will likely see a greater emphasis on ethical considerations as machine learning researchers and practitioners work to ensure that their models are fair and unbiased. This will involve developing new data collection and analysis techniques and new ways of ensuring that machine learning models are transparent and explainable.
Machine learning continues to mature, it will become an even more integral part of our daily lives, influencing everything from how we interact with technology to the jobs available. Professionals who understand machine learning and how to apply it will be in high demand, as they will drive innovation and growth in their respective fields.

Conclusion
Machine learning is not just a technological trend but a revolution changing how we live and work. For professionals in fields that require heavy computing, such as 3D rendering, architecture, and data science, machine learning can enhance efficiency, improve accuracy, and unlock new possibilities.
By embracing machine learning, these professionals can stay ahead of the curve and ensure they are well-equipped to face future challenges.
Sources:
- NVIDIA – What is Deep Learning?
- IBM Cloud – Machine Learning
- ScienceDirect – Machine Learning Algorithms
- Towards Data Science
- O’Reilly – Hands-On Machine Learning
Frequently Asked Questions:
-
How can businesses integrate machine learning into their operations?
Businesses can integrate machine learning by identifying areas where data analysis can improve efficiency, investing in machine learning platforms, and training staff on machine learning tools and techniques.
-
What are the ethical considerations when implementing machine learning?
Ethical considerations include ensuring that machine learning models are unbiased and transparent and respecting user privacy and data security.
-
How can one start a career in machine learning?
It involves gaining a strong foundation in computer science, statistics, and programming and hands-on experience with machine learning algorithms and tools.